Pick the right fully homomorphic encryption 2026 toolkit
Choosing a library depends on whether you prioritize raw speed, low-latency single operations, or ease of integration with existing machine learning pipelines. The landscape for fully homomorphic encryption 2026 tools has matured, but each library serves a different architectural need. Match your workload to the engine that handles it best.
OpenFHE: The General-Purpose Workhorse
OpenFHE is the most comprehensive open-source toolkit for general homomorphic encryption. It supports a wide range of schemes, including BFV, BGV, CKKS, and TFHE, making it ideal for complex circuits and multi-operation workflows. If your application requires heavy arithmetic or polynomial evaluation, OpenFHE provides the necessary primitives and optimizations.
TFHE: Low-Latency Gate Operations
TFHE (Torus Fully Homomorphic Encryption) excels at evaluating Boolean circuits with extremely low latency. It is the preferred choice for applications like private database lookups or simple conditional logic where speed per operation matters more than throughput. However, bootstrapping in TFHE can be resource-intensive, so it is less suited for deep arithmetic circuits without careful optimization.
Microsoft SEAL: Enterprise-Grade Stability
Microsoft SEAL is designed for robustness and ease of use in enterprise environments. It focuses on the BFV and CKKS schemes, offering high-level APIs that simplify implementation for developers who may not be cryptography experts. If your team needs a stable, well-documented library for financial or healthcare data analysis, SEAL is the safest bet.
Comparison of Key Libraries
Use this table to compare latency, supported operations, and integration ease across the top three open-source options.
| Library | Primary Use | Latency | Integration Ease |
|---|---|---|---|
| OpenFHE | General circuits | Medium | Moderate |
| TFHE | Boolean gates | Low | Hard |
| Microsoft SEAL | Enterprise apps | Medium-High | Easy |
Set up the development environment
Before writing any logic for fully homomorphic encryption 2026 projects, you need a clean workspace and the correct compiler toolchain. Most production-grade libraries rely on Rust or C++ with specific SIMD optimizations. Skipping these prerequisites often leads to silent performance degradation or build failures later.
Start by installing the base compilers and build tools. For Linux environments, this usually means build-essential or gcc/g++ versions 11 or newer. macOS users should install Xcode Command Line Tools. Windows developers need the Visual Studio Build Tools with C++ workload enabled. Ensure your system package manager is up to date to avoid missing shared libraries.
Install the primary language runtime. If you are using TFHE-rs or Concrete, install the latest stable Rust toolchain via rustup. For C++ libraries like OpenFHE, ensure you have CMake 3.18+ and a compatible compiler. Verify the installation by running rustc --version or cmake --version to confirm the binaries are in your PATH.
Clone your chosen library repository. Most libraries support a --recursive flag to pull submodules like TFHE or SEAL automatically. Build the library in release mode with optimization flags enabled. For Rust, use cargo build --release. For C++, run cmake --build . --config Release. This step compiles the heavy mathematical kernels required for encryption.
Run the library’s test suite to confirm everything works. Execute cargo test or ctest to validate the build. A successful run indicates that your SIMD instructions and memory alignment are correct. If tests fail, check your compiler version or ensure you have enough RAM, as FHE builds are memory-intensive.
Once the environment is verified, you are ready to write your first encryption script. The setup phase is critical because fully homomorphic encryption 2026 workflows are sensitive to compiler optimizations and memory management.
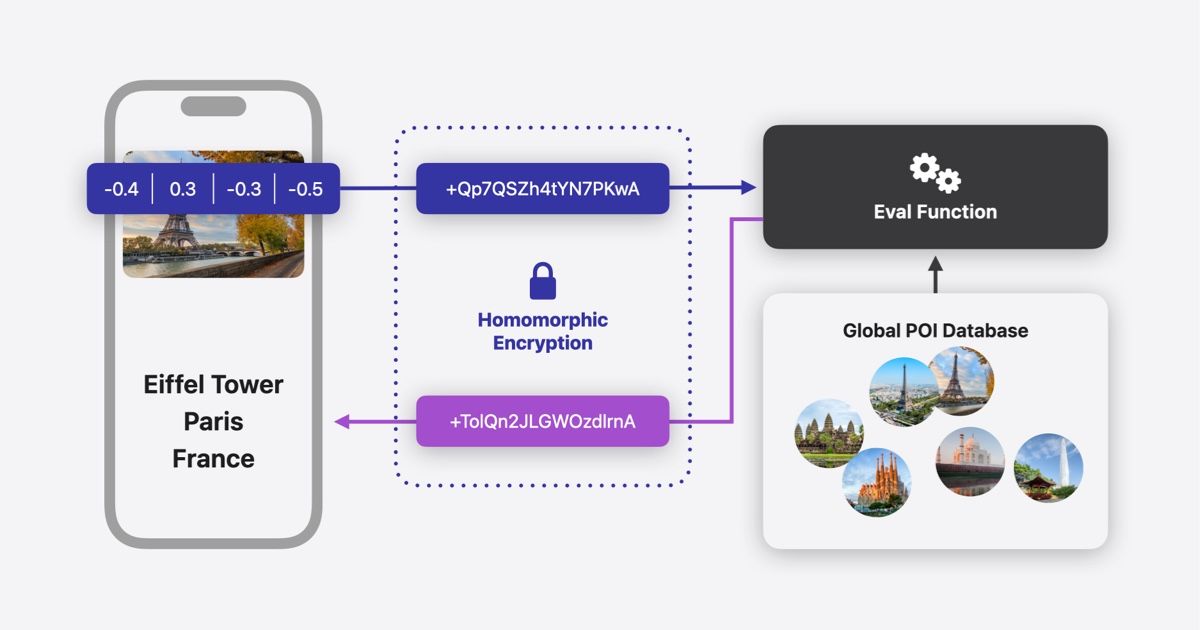
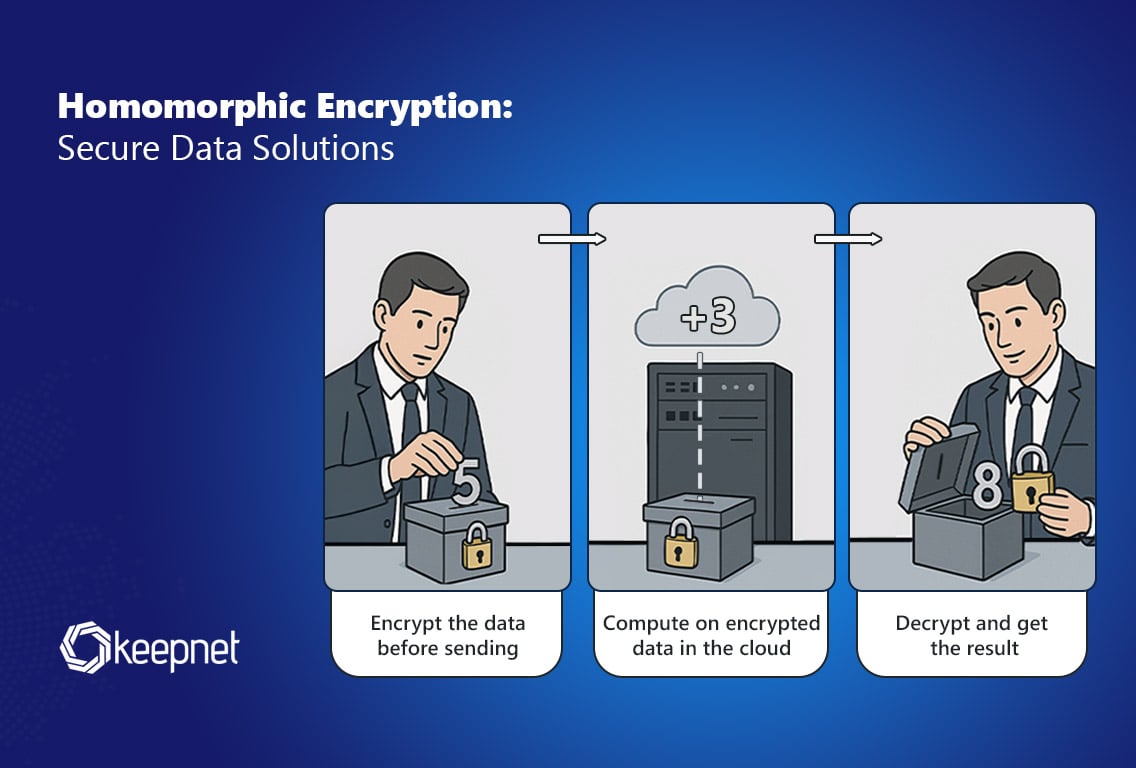
Encrypt data before model inference
Before passing sensitive inputs to a machine learning model, you must convert plaintext into ciphertext. This process, known as encryption, ensures the model processes only scrambled data. The security and performance of this step depend entirely on your parameter selection.
1. Select a parameter set
Choose a parameter set that balances security and computational cost. The Ring-LWE (Learning With Errors) scheme is the standard for fully homomorphic encryption 2026 implementations. You will need to define three core parameters:
- Polynomial degree ($N$): Determines the size of the data vectors. Higher $N$ allows larger datasets but increases computation time.
- Ciphertext modulus ($Q$): Defines the range of values the ciphertext can hold. A larger $Q$ supports more operations before noise becomes unmanageable.
- Error distribution ($\chi$): Controls the noise added to the data. Proper noise management is critical for accurate inference results.
For most 2026 applications, a polynomial degree of $N=4096$ or $N=8192$ provides a strong baseline. Start with these values and adjust based on your model’s complexity.
2. Initialize the encryption context
Load your chosen toolkit (e.g., SEAL, HElib, or TFHE) and initialize the encryption context with your selected parameters. This step creates the mathematical environment where all subsequent operations will occur. Ensure your toolkit supports the specific homomorphic operations required by your model, such as polynomial evaluation or matrix multiplication.
3. Encrypt the input data
Convert your plaintext input vectors into ciphertext. Each element of the input vector becomes a separate ciphertext or is packed into a single ciphertext using slot packing. Slot packing is more efficient for large datasets but requires careful alignment with the model’s input structure.
4. Verify ciphertext integrity
After encryption, perform a quick sanity check. Decrypt a sample ciphertext using the secret key to ensure the plaintext matches the original input. This step confirms that your encryption context is correctly configured and that no data corruption occurred during the conversion process.
Choose $N$, $Q$, and error distribution based on your security needs and model complexity. Start with $N=4096$ as a baseline.

Load your FHE toolkit and configure the encryption context with your chosen parameters. Ensure support for required homomorphic operations.
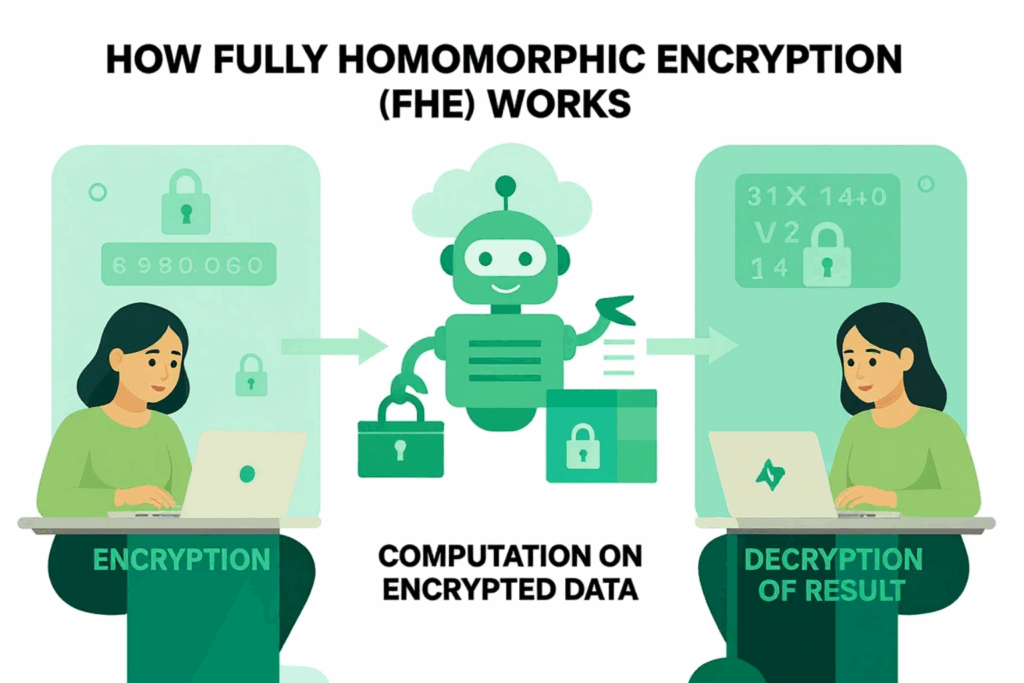
Convert plaintext vectors into ciphertext using slot packing for efficiency. Ensure alignment with the model’s input structure.
Decrypt a sample ciphertext to confirm the original plaintext is preserved. This validates your encryption context before inference.
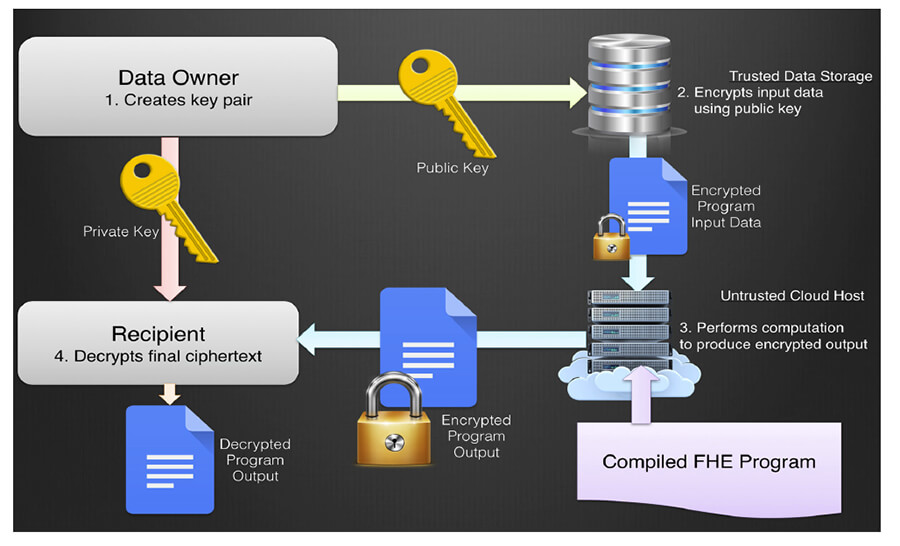
Run encrypted machine learning inference
Executing machine learning models on ciphertexts is the final hurdle in making fully homomorphic encryption 2026 practical for real-world applications. While training models on encrypted data remains computationally prohibitive, inference—the process of running a trained model against new data—has become viable for specific use cases.
The goal here is to take a pre-trained model, such as a logistic regression classifier or a small neural network, and perform the necessary arithmetic operations (additions and multiplications) on the encrypted input data. The output remains encrypted, ensuring that the data owner never sees the raw inputs or the model's intermediate states.
Choose a lightweight model
Start with a simple model. Logistic regression or a shallow neural network is ideal for demonstration because it requires fewer homomorphic operations than deep learning architectures. Complex models introduce massive computational overhead due to the depth of the circuit required.
Select a model that relies primarily on addition and multiplication. Avoid complex non-linear functions like ReLU or sigmoid, which require expensive bootstrapping or approximation techniques. Linear layers are the most efficient for encrypted inference.
Encrypt the input data
Use your chosen FHE library (such as OpenFHE or Microsoft SEAL) to encrypt the input vector. Ensure the plaintext encoding matches the model's expected input format. For example, if your model expects normalized float values, encrypt those specific normalized values.
Verify the encryption parameters (polynomial modulus degree, coefficient modulus) are set to handle the precision required for your model's weights. Insufficient precision will lead to noisy, inaccurate results.
Execute the inference circuit
Perform the matrix multiplication and addition operations using the FHE library's homomorphic arithmetic functions. This involves multiplying encrypted inputs by encrypted weights and summing the results.
This step is where the computational overhead becomes apparent. Homomorphic multiplication is significantly more expensive than plaintext multiplication. The ciphertext size grows with each operation, and the computation time can be orders of magnitude slower than plaintext inference.
Decrypt and interpret the result
Once the circuit is complete, decrypt the final ciphertext. The resulting plaintext is the model's prediction or score. Compare this against your plaintext inference results to verify accuracy.
Note that the decrypted result may contain small noise due to the nature of FHE. You may need to apply a threshold or rounding function to interpret the final classification or regression value correctly.
Fix common FHE performance bottlenecks
Even with modern libraries, fully homomorphic encryption 2026 implementations often stall under the weight of ciphertext noise. When noise grows too fast, the system fails to decrypt. You can prevent this by tightening your parameter selection and leveraging specialized hardware.
Tune parameters to limit noise growth
Noise is the enemy of homomorphic computation. Every multiplication adds more noise to the ciphertext. If you do not choose the right ring dimension and modulus chain, your program will crash before it finishes. Start with a small dataset to measure noise expansion, then scale up.
Use tools like TFHE or CTFE to simulate noise levels before deployment. Adjust the polynomial modulus degree to balance security and speed. A higher degree increases security but slows down operations significantly.
Enable hardware acceleration
Software-only FHE is often too slow for production workloads. Specialized hardware accelerators can speed up homomorphic operations by orders of magnitude. NYU Tandon researchers are developing specialized hardware accelerators for enabling computation on encrypted data, showing that custom silicon is the future of this field IEEE Spectrum.
If you do not have access to custom hardware, use GPU acceleration. Libraries like OpenFHE support CUDA, allowing you to offload heavy matrix operations to the GPU. This is often the easiest way to get a 10x performance boost.
Verify before deployment
Before you ship, run a comprehensive checklist to ensure your parameters are secure and your performance is acceptable.
No comments yet. Be the first to share your thoughts!