Choose your FHE toolkit
Selecting the right Fully Homomorphic Encryption (FHE) library requires balancing computational complexity against your specific workload. The three primary open-source options—Microsoft SEAL, OpenFHE (formerly HElib), and TFHE—serve distinct architectural needs. Your choice depends on whether your application relies on arithmetic operations or boolean logic, and the acceptable latency for your cloud-native deployment.
Comparison of FHE Libraries
The following table compares the core capabilities of the leading FHE libraries. Use this to align technical constraints with your use case.
| Library | Primary Operations | Latency Profile | Best Use Case |
|---|---|---|---|
| Microsoft SEAL | Arithmetic (RLWE) | High (ms to s) | ML inference, large datasets |
| OpenFHE | Arithmetic (RLWE) | High (ms to s) | Complex mathematical models |
| TFHE | Boolean (LWE) | Low (µs to ms) | Logic gates, small data |
Microsoft SEAL and OpenFHE: Arithmetic Workloads
Microsoft SEAL and OpenFHE are built on Ring Learning With Errors (RLWE) schemes. They excel at arithmetic operations like addition and multiplication, which are essential for machine learning inference and statistical analysis. However, these operations are computationally expensive. Encrypted matrix multiplications can take seconds or even minutes, depending on the parameter set.
Deploy these libraries in Kubernetes pods where latency is not the primary bottleneck. They are ideal for batch processing jobs or offline analytics where the cost of encryption overhead is acceptable compared to the privacy gain. OpenFHE offers a more extensive API surface for advanced cryptographic primitives, while SEAL provides a streamlined, production-tested interface.
TFHE: Boolean Logic and Low Latency
TFHE (Torus FHE) uses a different approach based on torus arithmetic and LWE schemes. It is optimized for boolean logic operations (AND, OR, NOT) rather than arithmetic. This makes it exceptionally fast for small-scale computations. Latency is measured in microseconds or low milliseconds, making it suitable for interactive applications.
Use TFHE when your workload involves conditional logic, such as encrypted search queries or access control checks. The trade-off is that scaling to large datasets or complex arithmetic circuits becomes difficult. It is best paired with other libraries in a hybrid architecture, handling the logic layer while SEAL or OpenFHE manages the heavy arithmetic lifting.
Integration Patterns for Cloud-Native Systems
Regardless of the library, FHE introduces significant memory and CPU overhead. In a containerized environment, ensure your pods have sufficient resource limits. Use sidecar containers to handle key generation and parameter setup, keeping the main application container focused on computation. Always test with realistic data volumes to determine the actual throughput before committing to a specific toolkit.
Integrate FHE into your cloud stack
Moving from plaintext to encrypted data handling requires rethinking your microservice boundaries. In a standard cloud-native pipeline, Fully Homomorphic Encryption (FHE) acts as a transparent layer that processes data without exposing keys or plaintext to the compute node. This section outlines a concrete workflow for integrating FHE into a Kubernetes-based infrastructure, focusing on practical deployment steps rather than theoretical cryptography.
The goal is to embed FHE operations directly into your application logic, ensuring that sensitive data remains encrypted in memory during computation. This approach shifts the security boundary from the network perimeter to the individual data fields, protecting against compromised infrastructure or insider threats.
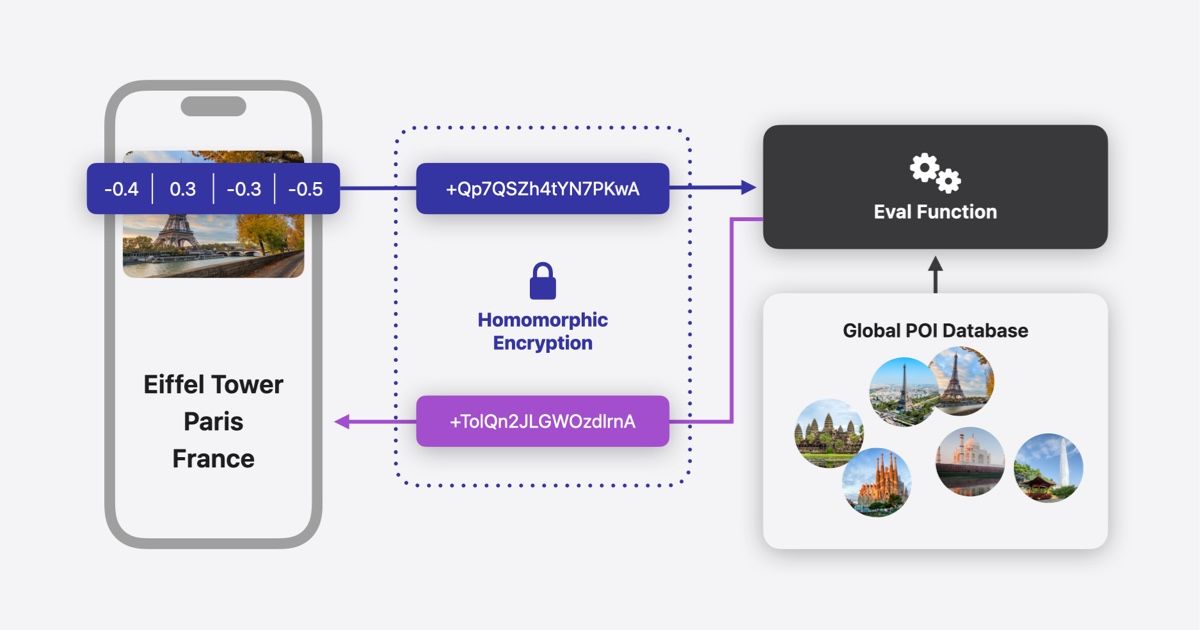
Begin by choosing an FHE library that supports your target programming language and hardware acceleration. Libraries like Microsoft SEAL or OpenFHE are common choices. Containerize the library dependencies to ensure consistent execution environments across your Kubernetes cluster. Use multi-stage builds to keep the final image lean, excluding unnecessary build tools and source code.
Map your plaintext data structures to their encrypted equivalents. Determine which fields require encryption based on sensitivity and regulatory requirements. Define the polynomial modulus degree and coefficient modulus in your FHE parameters, as these directly impact performance and security levels. Document these parameters in your service configuration, as they cannot be changed without re-encrypting existing data.
Generate and distribute FHE keys securely. In a cloud-native environment, use a dedicated secrets manager or a hardware security module (HSM) to store secret keys. Public keys can be shared openly for encryption, but secret keys must remain strictly controlled. Implement a key rotation policy that minimizes downtime by supporting parallel key versions during transition periods.
Deploy your application as a Kubernetes Deployment with appropriate resource limits. FHE computations are CPU-intensive; ensure your nodes have sufficient CPU resources and consider using dedicated nodes for FHE workloads. Configure liveness and readiness probes to monitor the health of the encryption services. Monitor latency and throughput metrics to identify bottlenecks in the homomorphic evaluation process.
The integration process involves significant overhead compared to plaintext processing. Expect computational latency to increase by orders of magnitude. To mitigate this, batch requests where possible and optimize your FHE parameters for the specific operations you perform. Regularly benchmark your encrypted services against your plaintext baselines to ensure performance meets your service level objectives (SLOs).
By following these steps, you establish a robust foundation for privacy-preserving compute in your cloud environment. This architecture ensures that data remains protected throughout its lifecycle, from ingestion to processing and storage.
Optimize for latency and cost
The primary barrier to adopting fully homomorphic encryption (FHE) is not security, but performance. Without optimization, FHE operations can be thousands of times slower than plaintext processing. To make FHE viable in 2026, engineers must aggressively target latency and cost through three levers: bootstrapping efficiency, batching, and hardware acceleration.
Reduce bootstrapping overhead
Bootstrapping refreshes ciphertexts to prevent noise accumulation, but it is computationally expensive. Optimize by selecting schemes with lower bootstrapping costs, such as BFV or CKKS variants tailored for specific workloads. Use lazy bootstrapping, where you delay the operation until noise thresholds are critical, rather than applying it after every step. This reduces the total number of bootstrapping events, directly cutting compute time.
Leverage batching for parallelism
FHE schemes support SIMD (Single Instruction, Multiple Data) operations. Instead of processing one data point at a time, pack multiple values into a single ciphertext and perform operations in parallel. For example, in a privacy-preserving AI inference, batch multiple user queries into one encrypted tensor. This amortizes the cost of homomorphic operations across many data points, improving throughput by orders of magnitude.
Accelerate with GPU and FPGA hardware
Software-only FHE is often too slow for real-time applications. Offload heavy linear algebra operations to GPUs, which excel at the parallel matrix multiplications common in FHE. For even higher efficiency, consider FPGAs, which can be customized to execute FHE-specific instructions with lower latency and power consumption. Cloud-native deployments should containerize these accelerators, using Kubernetes to schedule FHE workloads on nodes equipped with the necessary hardware.
By combining these strategies, you can transform FHE from a theoretical curiosity into a practical tool for private compute. The goal is not to eliminate the performance gap entirely, but to narrow it enough to make FHE deployments economically and technically feasible for your specific use case.
Running Inference on Encrypted Data
The most compelling application of Fully Homomorphic Encryption (FHE) in 2026 is privacy-preserving AI inference. This approach allows cloud providers to run machine learning models on encrypted user data without ever decrypting it, ensuring that the model weights and the input data remain confidential throughout the computation.
Adapting Models for FHE
Standard deep learning models rely on floating-point arithmetic and non-linear activation functions like ReLU, which are computationally expensive or difficult to implement in FHE. To make inference practical, engineers typically use quantized models that convert weights and activations to fixed-point integers. This reduces the noise growth during homomorphic operations, allowing for deeper networks without overwhelming the ciphertext.
Activation functions are often replaced with approximations that are easier to compute homomorphically, such as piecewise linear functions or low-degree polynomials. While this introduces minor accuracy degradation, the trade-off is acceptable for many classification and regression tasks where privacy is paramount.
Cloud-Native Deployment
Deploying FHE-enabled inference requires a specialized infrastructure to handle the high computational overhead. Kubernetes clusters are often configured with dedicated nodes equipped with multi-threaded CPU optimizations or hardware accelerators like GPUs and FPGAs that support SIMD (Single Instruction, Multiple Data) operations for batched FHE computations.
Containers are used to isolate the inference service, ensuring that the FHE libraries and model weights are securely loaded and managed. The architecture typically involves a client-side encryption module, a secure API gateway, and the FHE inference engine running within a protected environment. This setup allows organizations to offer "privacy-first" AI services, where users can query models without exposing their sensitive data to the service provider.
Accuracy vs. Speed Trade-offs
Current FHE inference speeds are significantly slower than plaintext execution, often by a factor of 100 to 1,000. However, advancements in bootstrapping techniques and optimized libraries have narrowed this gap. Accuracy remains high for quantized models, with most practical applications seeing less than a 1-2% drop in performance compared to unencrypted counterparts. This balance makes FHE viable for high-value use cases such as healthcare diagnostics, financial fraud detection, and secure biometric authentication.
Prepare for production deployment
Moving fully homomorphic encryption (FHE) from a research prototype to a production workload requires rigorous operational discipline. The computational overhead of encrypted compute means that standard cloud-native monitoring and security postures must be adapted to handle the unique characteristics of ciphertext-based operations.
Operational Readiness Checklist
Before scaling your FHE services, verify the following production requirements:
- Key Management Lifecycle: Implement automated rotation for secret keys and public parameters. Ensure key storage integrates with your existing HSM or KMS provider to prevent single points of failure.
- Compliance Verification: Confirm that your data processing workflows meet regulatory standards (GDPR, HIPAA) by documenting the cryptographic boundaries of your encrypted compute environment.
- Encrypted Workload Monitoring: Deploy observability tools that can track latency and memory usage of ciphertext operations without decrypting the data. Set alerts for performance degradation caused by FHE bootstrapping cycles.
- Kubernetes Resource Quotas: Configure HPA (Horizontal Pod Autoscaler) policies that account for the high CPU and memory spikes typical of FHE inference or training tasks.
No comments yet. Be the first to share your thoughts!